Оптимизация страниц тегов и фильтров в интернет-магазине — как избежать мусорной индексации
Статья 52
Введение
Представьте: ваш интернет-магазин имеет 500 товаров, но поисковый робот видит 50 000 страниц. Откуда? Из фильтров, сортировок и тегов, которые генерируют тысячи URL с почти одинаковым содержимым. Результат — поисковик тратит ресурсы на сканирование «мусора», а действительно важные страницы теряют позиции.
Страницы тегов и страницы фильтров — мощный инструмент для пользователей и для SEO. Но только если они правильно настроены. При неправильной реализации возникают дубли страниц, раздувается индекс, а краулинговый бюджет (количество страниц, которое робот готов просканировать за визит) сжигается впустую.
Эта статья — пошаговое руководство по оптимизации интернет-магазина с точки зрения управления индексацией фильтров и тегов. Внутри: конкретные примеры кода, сравнительные таблицы методов, специфика Яндекса и Google, а также чек-лист для самопроверки. Материал будет полезен владельцам магазинов, SEO-специалистам среднего уровня и разработчикам, которые реализуют техническую часть.
Что такое страницы тегов и фильтров и почему они создают проблемы индексации
Прежде чем бороться с мусорной индексацией, нужно понять, откуда берутся лишние URL и почему поисковики воспринимают их как проблему.

Как формируются страницы фильтров в интернет-магазине
Страницы фильтров появляются, когда пользователь выбирает параметры в фасетной навигации — бренд, цвет, размер, ценовой диапазон. Каждая комбинация фильтров генерирует уникальный URL с GET-параметрами.
Примеры типичных URL:
- /catalog/smartphones/?brand=samsung&color=black
- /catalog/smartphones/?brand=samsung&color=black&price=10000-20000
- /catalog/smartphones/?sort=price&page=2&brand=apple
Проблема в математике: если у вас 5 брендов, 8 цветов, 4 ценовых диапазона и 3 варианта сортировки — это уже 5×8×4×3 = 480 комбинаций URL только для одной категории. Добавьте пагинацию, и число вырастет в разы.
Страницы тегов — в чём отличие от фильтров
Страницы тегов — это статические подборки товаров, объединённых по определённому признаку. В отличие от фильтров, теги создаются вручную или полуавтоматически и имеют чистые URL:
- /catalog/smartphones/samsung-black/
- /catalog/nedorogie-smartfony/
Когда теги полезны для SEO: если под тег есть поисковый спрос (например, «недорогие смартфоны Samsung»), страница получает уникальный title, описание и текст. Когда теги вредят: если создаются бездумно, без привязки к семантике — десятки пустых подборок засоряют индекс точно так же, как и фильтры.

Главная проблема — дубли страниц и мусорная индексация
Дубли страниц в контексте фильтров — это URL с разным адресом, но практически идентичным контентом. Для поискового робота /catalog/?color=black&brand=samsung и /catalog/?brand=samsung&color=black — две разные страницы с одинаковым содержимым.
Реальные последствия:
- Размытие ссылочного веса. Внешние и внутренние ссылки распределяются между дублями вместо того, чтобы усиливать одну целевую страницу.
- Просадка позиций. Поисковик не понимает, какую версию ранжировать, и может выбрать не ту — или понизить все.
- Потеря краулингового бюджета. Робот сканирует тысячи мусорных URL и не доходит до важных карточек товаров.
По данным Google Search Central, для крупных сайтов с более чем 10 000 страниц управление краулинговым бюджетом становится критически важным фактором.

Аудит текущего состояния — как выявить проблемы индексации страниц фильтров и тегов
Любая оптимизация начинается с диагностики. Нельзя чинить то, что не измерено.
Проверка индексации страниц через Google Search Console и Яндекс Вебмастер
Откройте Google Search Console → раздел «Страницы» (бывший «Покрытие»). Обратите внимание на:
- Количество проиндексированных страниц. Если их в 10 раз больше, чем реальных товаров и категорий — у вас проблема.
- Страницы с пометкой «Обнаружено, не проиндексировано» и «Просканировано, не проиндексировано» — часто именно здесь скапливаются фильтрационные URL.
В Яндекс Вебмастере проверьте раздел «Индексирование» → «Страницы в поиске». Яндекс также показывает исключённые страницы и причины исключения.
Совет: используйте оператор site:вашдомен.ru inurl:? в поисковой строке Google, чтобы увидеть проиндексированные URL с GET-параметрами.

Анализ краулингового бюджета и логов сервера
Логи сервера — самый точный источник данных о поведении поисковых роботов. Вы увидите, какие URL сканируются чаще всего. Если 80% запросов Googlebot приходится на параметрические адреса фильтров — бюджет расходуется неэффективно.
Для анализа логов подойдут Screaming Frog Log File Analyser или бесплатный GoAccess.

Инструменты для обнаружения дублей страниц
Три проверенных инструмента:
- Screaming Frog SEO Spider — сканирует сайт и показывает дубли по title, H1, контенту. Позволяет фильтровать URL с параметрами.
- Netpeak Spider — аналогичный функционал с удобным интерфейсом, хорошо работает с крупными сайтами.
- Sitebulb — визуализирует структуру сайта и наглядно показывает кластеры дублей.
Запустите полный краул с включёнными параметрами — так вы увидите реальный масштаб проблемы.

Стратегии оптимизации страниц фильтров для SEO интернет-магазина
Это ключевой раздел. Здесь — конкретные методы решения проблемы с пояснением, когда какой применять.
Какие страницы фильтров оставить открытыми для индексации
Не все фильтры — мусор. Некоторые страницы фильтров имеют реальный поисковый спрос и приносят трафик. Критерии отбора:
- Поисковый спрос. Проверьте в Яндекс Wordstat и Google Keyword Planner. Если запрос «смартфоны Samsung чёрные» имеет 500+ показов в месяц — страница ценна.
- Уникальность контента. Страница фильтра должна содержать набор товаров, который существенно отличается от родительской категории.
- Коммерческая ценность. Фильтр по бренду + категория почти всегда ценнее, чем фильтр по цвету + сортировке.
Практический подход: открывайте для индексации фильтры первого уровня (бренд, тип товара) и закрывайте комбинации второго уровня и глубже (бренд + цвет + цена + сортировка).
Настройка robots.txt для закрытия мусорных URL
Файл robots.txt — первый рубеж обороны. Он сообщает роботам, какие разделы сканировать не нужно.
Настройка robots.txt подразумевает добавление правил Disallow для параметрических URL:
Пример настройки robots.txt для интернет-магазина
- User-agent: *
- Disallow: /*?sort=
- Disallow: /*?page=
- Disallow: /*&color=
- Disallow: /*&price=
- Disallow: /*?utm_
- # Для Яндекса — директива clean-param
- User-agent: Yandex
- Clean-param: sort&page&color&price&utm_source&utm_medium /catalog/

Важно: директива Clean-param — специфика Яндекса. Она сообщает роботу, что указанные параметры не влияют на контент страницы. Google эту директиву не поддерживает.
Ограничения robots.txt: этот метод не гарантирует удаление из индекса. Если на мусорную страницу ведут внешние ссылки, поисковик может её проиндексировать, проигнорировав запрет. Robots.txt блокирует сканирование, но не индексацию.
Использование канонических страниц (rel=canonical)
Канонические страницы (тег rel=canonical) указывают поисковику, какую версию URL считать основной. Это главный инструмент борьбы с дублями.
Когда использовать canonical:
- Страница фильтра отображает тот же набор товаров, что и основная категория (например, сортировка не меняет контент).
- Несколько URL ведут к одному и тому же результату.
Пример в HTML:
- <!-- На странице /catalog/smartphones/?sort=price -->
- <link rel="canonical" href="https://example.ru/catalog/smartphones/" />
Типичные ошибки при настройке canonical:
- Указание canonical на страницу с редиректом или на 404.
- Указание canonical на страницу, которая сама имеет noindex.
- Цепочки canonical: A → B → C. Всегда указывайте на конечную каноническую страницу.
- Разные canonical в HTML и HTTP-заголовке.

Мета-тег noindex, follow — когда применять
Мета-тег <meta name="robots" content="noindex, follow"> запрещает индексацию конкретной страницы, но разрешает роботу переходить по ссылкам на ней.
Отличие от robots.txt: noindex работает на уровне страницы и гарантирует удаление из индекса, тогда как robots.txt блокирует лишь сканирование. Отличие от canonical: canonical перенаправляет вес на основную страницу, а noindex просто исключает URL из выдачи.
Когда применять noindex:
- Страницы с комбинацией 3+ фильтров.
- Страницы пагинации в фильтрах (за исключением первой).
- Страницы сортировки, не имеющие поискового спроса.
- <meta name="robots" content="noindex, follow">
Управление параметрами URL в Google Search Console
В Google Search Console раньше был инструмент «Параметры URL». В 2024 году Google перевёл его в ограниченный режим, но вы всё ещё можете задать поведение для конкретных GET-параметров: сканировать / не сканировать, влияет / не влияет на контент.
Для Яндекса аналогичную функцию выполняет директива Clean-param в robots.txt.
Сводная таблица сравнения методов
| Метод | Блокирует сканирование | Убирает из индекса | Передаёт вес | Поддержка Яндекс | Поддержка Google |
| Robots.txt Disallow | ✅ | ❌ | ❌ | ✅ | ✅ |
| Canonical | ❌ | Косвенно | ✅ | ✅ | ✅ |
| Noindex, follow | ❌ | ✅ | Частично | ✅ | ✅ |
| Clean-param | ❌ | Косвенно | ❌ | ✅ | ❌ |
| Параметры в GSC | Зависит | Зависит | ❌ | ❌ | ✅ (ограниченно) |
Рекомендация: для максимальной надёжности комбинируйте методы. Оптимальная связка для мусорных фильтров: noindex, follow + исключение из sitemap.xml. Для страниц-дублей с ценностью: rel=canonical на основную версию.
Оптимизация страниц тегов — пошаговое руководство

Страницы тегов требуют иного подхода, чем фильтры. Если фильтры нужно преимущественно закрывать, то теги — целенаправленно развивать.
Как создать SEO-ценные теговые страницы
Каждая теговая страница, оставленная в индексе, должна быть полноценной посадочной страницей:
- Уникальный Title: «Купить [тег] в Москве — каталог с ценами | Магазин». Не шаблонные title вида «Тег — Магазин».
- Уникальный Description: раскройте выгоду для пользователя, упомяните количество товаров, ценовой диапазон.
- Уникальный H1: отличающийся от title, но содержащий целевой запрос.
- Текстовый контент: 300–800 символов уникального текста — краткое описание подборки, советы по выбору. Не «SEO-простыня» на 5000 знаков, а реально полезный абзац.
SEO-продвижение
Хотите получать заявки из поиска?
от 45 000 руб / мес
Комплексная работа над ростом позиций, трафика и заявок: техническая оптимизация, семантика, структура сайта, контент и регулярная аналитика.
Внутренняя перелинковка теговых страниц
Теговые страницы работают только при грамотной перелинковке:
- Размещайте блок тегов на страницах категорий — так робот быстро их обнаружит.
- Ставьте ссылки на теги из карточек товаров: «Смотрите также: чёрные смартфоны Samsung».
- Связывайте теги между собой, если они тематически близки.
Контроль количества тегов — как не раздуть индекс
Правило: количество тегов должно быть пропорционально ассортименту. Для магазина с 500 товарами 50–100 тегов — разумный максимум. Каждый тег — под конкретный поисковый запрос с подтверждённым спросом.
Если тег содержит менее 3 товаров — скорее всего, он не нужен. Если два тега показывают одинаковую выборку — один из них нужно объединить или удалить.
Техническая реализация — чек-лист для разработчика
Этот раздел — задание для разработчика, которое можно передать «как есть».
Настройка canonical, noindex и robots.txt — сводная таблица решений
| Тип URL | Метод | Пример |
| Категория (основная) | Canonical на себя | <link rel="canonical" href="/catalog/smartphones/" /> |
| Фильтр 1 уровня (с трафиком) | Canonical на себя, включить в sitemap | /catalog/smartphones/samsung/ |
| Фильтр 2+ уровней | Noindex, follow + исключить из sitemap | /catalog/?brand=samsung&color=black |
| Сортировка, пагинация | Canonical на первую страницу категории | /catalog/smartphones/?sort=price |
| Тег с поисковым спросом | Canonical на себя, уникальный контент | /catalog/nedorogie-smartfony/ |
| Тег без спроса | Noindex, follow или удалить | — |
Генерация sitemap.xml только для целевых страниц
В файл sitemap.xml включайте только те URL, которые должны попасть в индекс. Это прямой сигнал поисковику: «вот мои важные страницы». Никаких параметрических адресов, отфильтрованных URL или пагинации.
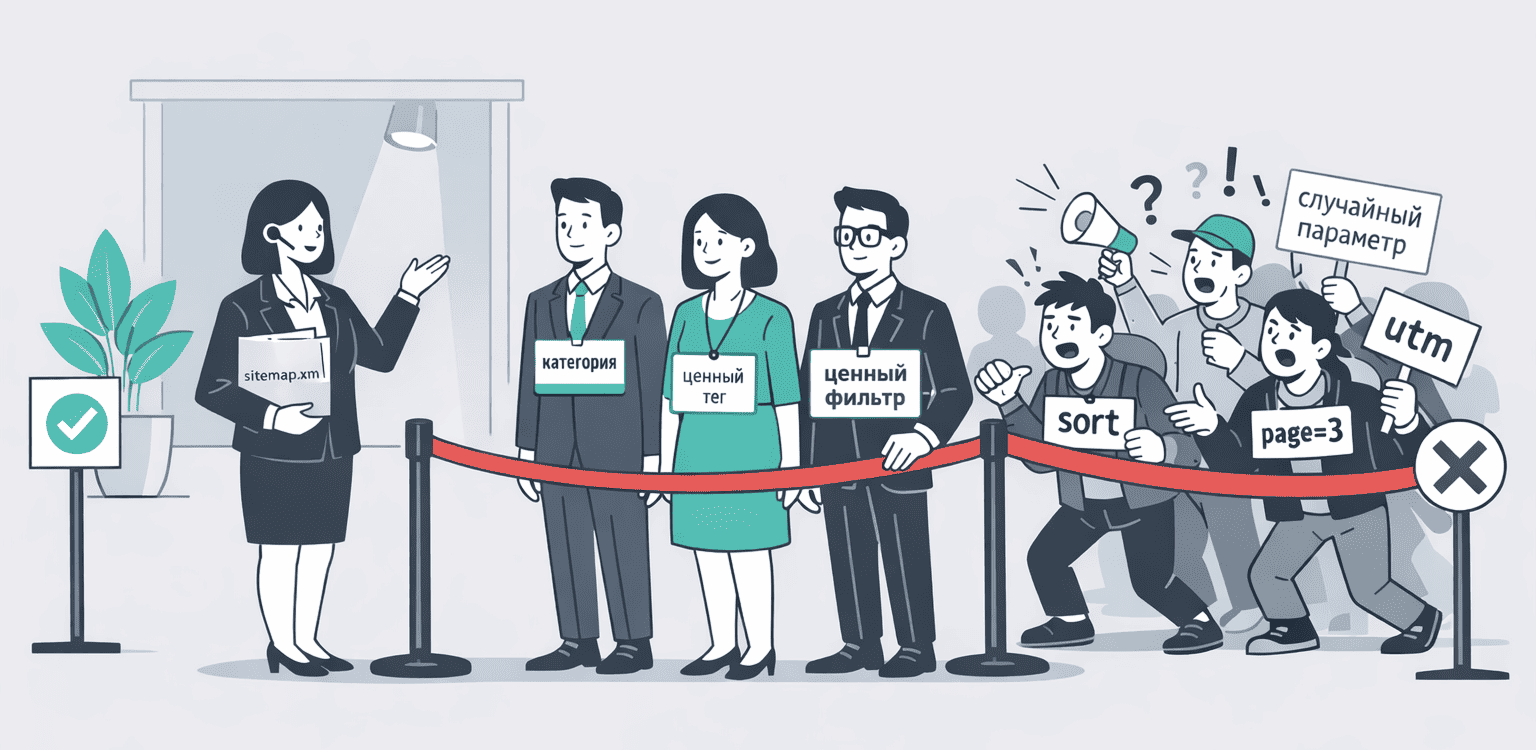
Автоматизируйте генерацию: sitemap должен обновляться при добавлении/удалении товаров и тегов.
AJAX-фильтры и хеш-навигация как альтернатива
Один из радикальных способов — не создавать параметрические URL вообще. AJAX-фильтры обновляют контент без изменения URL, а хеш-навигация (/catalog/#brand=samsung) не индексируется поисковиками.
Минус: вы теряете возможность получать трафик на ценные комбинации фильтров. Поэтому оптимальный подход — гибридный: ценные фильтры имеют статические ЧПУ, остальные работают через AJAX.
Пагинация в фильтрах — rel=prev/next и альтернативы
Google официально заявил, что больше не использует rel=prev/next как сигнал. Однако Яндекс по-прежнему их учитывает. Рекомендация: для пагинации в фильтрах ставьте canonical на первую страницу серии или используйте noindex на страницах 2+.
Частые ошибки при оптимизации интернет-магазина и как их избежать
Закрытие в robots.txt без noindex — почему страницы всё равно попадают в индекс
Это самая распространённая ошибка. Вы прописали Disallow в robots.txt, но через месяц найти страницы фильтров в выдаче можно по-прежнему. Причина: если на закрытый URL ссылаются другие сайты или внутренние страницы, поисковик может проиндексировать его, даже не сканируя содержимое. В индексе появится «пустая» страница с title из анкора ссылки.
Решение: комбинируйте robots.txt с noindex — первое снижает нагрузку на краулинговый бюджет, второе гарантирует исключение из индекса.
Конфликт canonical и noindex на одной странице
Если страница имеет noindex и одновременно canonical на другой URL — это противоречивые сигналы. Noindex говорит «не индексируй меня», а canonical — «индексируй, но считай основной вот ту». Google в такой ситуации может игнорировать оба сигнала.

Правило: на одной странице — один метод. Если страница мусорная — только noindex. Если она дубль ценной — только canonical.
Полное закрытие фильтров — потеря трафикового потенциала
Некоторые SEO-специалисты идут по пути наименьшего сопротивления и закрывают все фильтры от индексации. Это безопасно, но неэффективно. Вы теряете трафик по низкочастотным коммерческим запросам, которые конвертируются лучше высокочастотных.
Решение: всегда начинайте с анализа спроса. Выделите 10–20% фильтров с трафиковым потенциалом и оформите их как полноценные посадочные страницы.
Игнорирование Яндекса при настройке (особенности clean-param)
Многие руководства ориентированы на Google и забывают про Яндекс. А ведь в российском e-commerce доля Яндекса — около 60%. Директива Clean-param — мощный инструмент, который сообщает роботу Яндекса, что определённые параметры URL не влияют на содержимое страницы.
Синтаксис в robots.txt:
- Clean-param: sort&page&view /catalog/
- Это скажет роботу: все URL вида /catalog/?sort=X&page=Y&view=Z эквивалентны /catalog/.
Пошаговый алгоритм действий — от аудита до результата
Шаг 1: Аудит текущих страниц тегов и фильтров. Просканируйте сайт Screaming Frog, проверьте данные в Google Search Console и Яндекс Вебмастере. Зафиксируйте общее число проиндексированных URL и долю параметрических страниц.
Шаг 2: Сегментация URL на ценные и мусорные. Выгрузите все уникальные URL с параметрами. Проверьте каждую группу параметров в Яндекс Wordstat: есть спрос — ценная страница, нет спроса — мусорная.
Шаг 3: Выбор метода закрытия для каждого сегмента. Используйте сводную таблицу из раздела выше. Ценные фильтры → статические ЧПУ + canonical на себя. Мусорные комбинации → noindex, follow. Сортировки и служебные параметры → Disallow в robots.txt + Clean-param для Яндекса.
Шаг 4: Техническая реализация. Передайте разработчику чек-лист. Обновите robots.txt, добавьте canonical и noindex в шаблоны, пересоберите sitemap.xml.
Шаг 5: Мониторинг индексации и корректировка. Через 2–4 недели проверьте индексацию страниц заново. Число мусорных URL в индексе должно снижаться. Если нет — пересмотрите реализацию и найдите ошибки через оператор site:
Заключение
Проблемы индексации страниц фильтров и тегов — одна из главных технических болей любого интернет-магазина. Но решение не в том, чтобы закрыть всё подряд, а в грамотной сегментации: ценные страницы развивать как посадочные, мусорные — исключать из индекса комбинацией noindex, canonical и robots.txt.

Ключевые принципы SEO для интернет-магазина в контексте фильтрации:
- Один URL — один набор контента.
- Каждый открытый для индексации URL должен иметь подтверждённый поисковый спрос.
- Один метод управления индексацией на одну страницу — без конфликтов.
- Учитывайте специфику и Google, и Яндекса.
Чек-лист для самопроверки
- Проведён аудит числа проиндексированных страниц в GSC и Яндекс Вебмастере.
- Определены URL фильтров с поисковым спросом.
- Ценные фильтры оформлены как статические страницы с ЧПУ.
- На ценных страницах тегов — уникальные title, description, H1 и текст.
- Мусорные комбинации фильтров имеют мета-тег noindex, follow.
- Настроен canonical для страниц сортировки и пагинации.
- В txt прописаны Disallow для служебных параметров.
- Добавлена директива Clean-param для Яндекса.
- xml содержит только целевые URL.
- Нет конфликтов canonical + noindex на одной странице.
- Внутренняя перелинковка ведёт на ценные теги, а не на мусорные
- AJAX/хеш-навигация используется для неценных фильтров.
- Настроен мониторинг: повторная проверка через 2–4 недели.
- Логи сервера проанализированы — роботы не тратят бюджет на мусор.

FAQ — ответы на частые вопросы
Можно ли полностью закрыть все фильтры от индексации? +
Как быстро Google и Яндекс уберут мусорные страницы из индекса? +
Чем отличается подход к страницам тегов и фильтров? +
Нужно ли делать уникальный контент на каждую страницу фильтра? +
Пусть ваши теги приносят только целевой трафик, а роботы поисковых систем индексируют исключительно то, что приносит продажи — удачи в настройках!



Обсудим Ваш проект